Retrieval-Augmented Generation (RAG) is a groundbreaking approach that supercharges large language models (LLMs) with pinpoint accuracy and up-to-date information. RAG bridges the gap between an LLM’s broad understanding and specific, often proprietary information. It allows these powerful models to reference external sources before generating a response, ensuring outputs are not just fast, but precise and relevant. Imagine an AI that doesn’t just rely on its initial training, but fact-checks against the latest data in real-time. That’s RAG in action. It enhances LLMs to handle specific domains or tap into an organization’s internal knowledge, all without the need for constant model retraining. With RAG, you get the best of both worlds – the lightning-fast reasoning of advanced language models, combined with the accuracy and relevance of curated information. It’s a cost-effective way to dramatically improve AI outputs, making them more reliable, current, and tailored to specific contexts. Basically, RAG transforms AI from a generalist to a specialist, armed with the most recent and pertinent information for every query
Why can’t we use LLM models like ChatGPT to answer all of our questions?
Large Language Models (LLMs) like ChatGPT are impressive, no doubt. Their performance is often measured by the number of parameters they possess – ChatGPT, for instance, boasts a whopping 175 billion parameters. These parameters are the backbone of the AI’s language fluency, determining how it processes input and constructs output. Basically, they’re what make these models so good at mimicking human conversation.
But there is some drawback from using LLMs:
LLMs excel at answering general questions at lightning speed. However, when it comes to niche topics or specific, up-to-date information, they often fall short.
Hallucination: When faced with a query they can’t accurately answer, LLMs have an unfortunate tendency to fabricate information. They’ll confidently present false data rather than admitting ignorance.
Each LLM has a knowledge cutoff date. Any events or discoveries after this date are a complete blank to the model.
Questionable sources: LLMs are trained on wide rage of internet data, including sources like Wikipedia. While useful, these aren’t always the most reliable or authoritative sources of information.
This is where RAG steps in as a game-changer. It addresses these limitations by anchoring an LLM’s responses to a curated pool of data. This could include authoritative sources, fact-checked information, up-to-the-minute data, internal emails, official documentation – you name it. RAG essentially gives the LLM a set of trusted, relevant reference materials to work with, dramatically improving its accuracy and relevance for specific use cases.”
Why RAG is a Game-Changer?
Integrating RAG into your business is transformative. Here’s why:
Fast and affordable: Implementing a basic RAG framework is surprisingly quick – we’re talking a few lines of code in some cases. It leverages pre-existingFoundation Models (FMs) like GPT-3.5, GPT-4, or open-source options such as LLama2 and LLama3. These powerhouses, accessible via API, come pre-loaded with billions of trained parameters. It’s a cost-effective shortcut to customized AI, sidestepping the need to build and train a model from scratch. You’re tapping into a vast knowledge base that already understands natural language.
One framework, multiple chatbots: With RAG, your existing resources – company guidelines, tech manuals, FAQs, video transcripts, log data – become fuel for multiple AI applications. Set up LLMs with RAG to create specialized bots for employee training, manual summarization, or customer support. No more relying on human experts to sift through mountains of documents for every query.
Always in the know: Keep your AI current without the headache of constant retraining. Just update your documents, and your RAG-enhanced LLM stays in the loop. It’s like having an AI assistant that reads your latest memos in real-time.
Boosting AI credibility: RAG allows AI to tap into controllable, fact-checked sources. The output can include references or citations, significantly upping the trust factor. It’s like giving your AI a professional fact-checker.
More control, easier debugging: Testing with a small dataset lets developers quickly verify the AI’s accuracy. For the security-conscious, open-source models like LLaMa2 or LLama3 allow for local hosting of LLM+RAG setups. This means you can train on confidential data, fine-tune the LLM source to adapt to information changes, and implement granular access controls.
In essence, RAG isn’t just an upgrade – it’s a complete overhaul of how businesses can leverage AI, making it more accurate, adaptable, and trustworthy.
How RAG Works: The Open-Book Test Analogy
Imagine an LLM as a bright student taking an open-book test without preparation. They’ve absorbed some knowledge from class and do their best to recall it. Now, picture RAG as that same student, but fully prepared. For each question, they combine their classroom knowledge with the ability to flip to the exact page in their textbook for the most accurate answer.
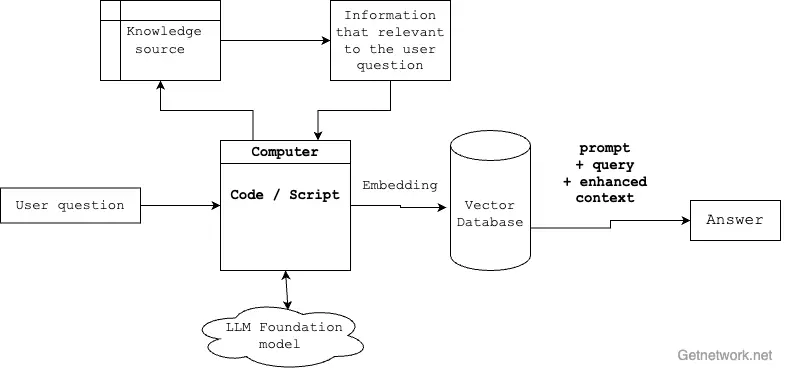
Retrieval-augmented generation (RAG) in LLMs with word embedding models and vector databases.
Here’s the behind-the-scenes magic of RAG:
Loading the External Library: Think of this as stocking the student’s backpack with carefully chosen books for the exam. Using tools like the Langchain Community, an open-source library, developers can load PDFs and various data formats, creating a curated knowledge base for the AI.
Smart Information Retrieval: When a question comes in, RAG doesn’t just randomly flip through its “textbooks.” It uses a technique called Word Embedding, a Natural Language Processing (NLP) technique, to convert both the question and the external data into numerical vectors. Allows the system to quickly find the most relevant information by measuring similarity between the question and available data.
Enhancing the LLM’s Answer: Here’s where RAG truly shines. It takes the user’s query, combines it with the relevant retrieved data, and then leverages the LLM’s natural language processing abilities. The result? An answer that’s not just fast, but accurate and grounded in verified data.
Staying Current: Let’s say the “textbook” gets updated – maybe a user manual for a product changes. No problem! RAG simply reloads the new external source (step 1), without needing to alter the rest of the process. You can even automate this, ensuring real-time updates whenever your source material changes.
Generate the “I don’t know” answer
One of the biggest issues with LLM chatbots is their reluctance to admit that they don’t know the answer. When faced with a question beyond their knowledge scope, these models often resort to generating plausible-sounding but potentially inaccurate responses. It’s like a student who, rather than admitting they don’t know an answer, tries to cobble together a response from vaguely related information. This issue gets worse because people often ask unclear or confusing questions, which can trip up even the smartest AI models.
RAG addresses this issue head-on by grounding responses in a specific, curated pool of information. Here’s the game-changer: with careful tuning and control, we can train LLM models to do something remarkably human – admit when they’re stumped or don’t have a reliable answer.
Imagine an AI that says, “Based on the information available to me, I don’t have a definitive answer to that question,” instead of spinning a web of potentially false information. This level of honesty and precision is why tech giants like IBM, NVIDIA, AWS, and Microsoft are now leveraging RAG to enhance their LLM models.
The potential is enormous. For internal support, it means employees get accurate information or a clear “I don’t know” rather than potentially misleading guidance. For customer-facing applications, it builds trust by providing reliable answers or honest admissions of limitations.
RAG isn’t just improving AI responses; it’s revolutionizing the very nature of human-AI interaction by introducing a crucial element: trustworthy uncertainty. In a world where misinformation can spread like wildfire, an AI that knows when to say “I don’t know” isn’t just smart – it’s responsible.
Get the best tech tips, AI tool reviews, and more to your email.
You will receive the best editors’ picks from all of our stories, stay tune!